April 2026
Aligned Information Bottleneck for Multimodal Social Sentiment Analysis
Abstract
Multimodal sentiment analysis (MSA) infers affect from synchronized text, speech, and visual signals, but it still faces cross-modal misalignment and noisy fusion, especially in naturalistic social communication. Differences in temporal resolution, semantic granularity, and modality-specific noise mean that simple concatenation or coarse interaction can amplify redundant cues from one modality while weakening informative signals from others. Recent approaches based on the Information Bottleneck (IB) principle help reduce redundancy. However, matrix-based Rényi-entropy estimators typically rely on a fixed low-rank truncation, making the resulting bottleneck sensitive to spectrum variation across batches, modalities, and difficulty levels. We propose a text-anchored IB framework for MSA that jointly addresses alignment and fusion. First, we construct a language-centered semantic space using a pretrained Qwen-3 encoder and map acoustic and visual features into this space, yielding an Aligned Information Bottleneck Representation that reduces cross-modal semantic gaps before fusion. Second, we introduce an Energy-Adaptive Low-Rank Rényi-entropy based Information Bottleneck. It builds on matrix-based Rényi-entropy estimators and selects the effective rank via an energy criterion. This suppresses redundant directions while preserving label-relevant structure. We evaluate the proposed framework on standard utterance-level MSA benchmarks with text, audio, and video. Extensive experiments and ablation studies show that our method improves over strong baselines across standard evaluation metrics. We also observe better robustness under modality noise and imbalance, supporting the value of text-anchored alignment and energy-adaptive low-rank IB for multimodal affect modeling.
Motivation
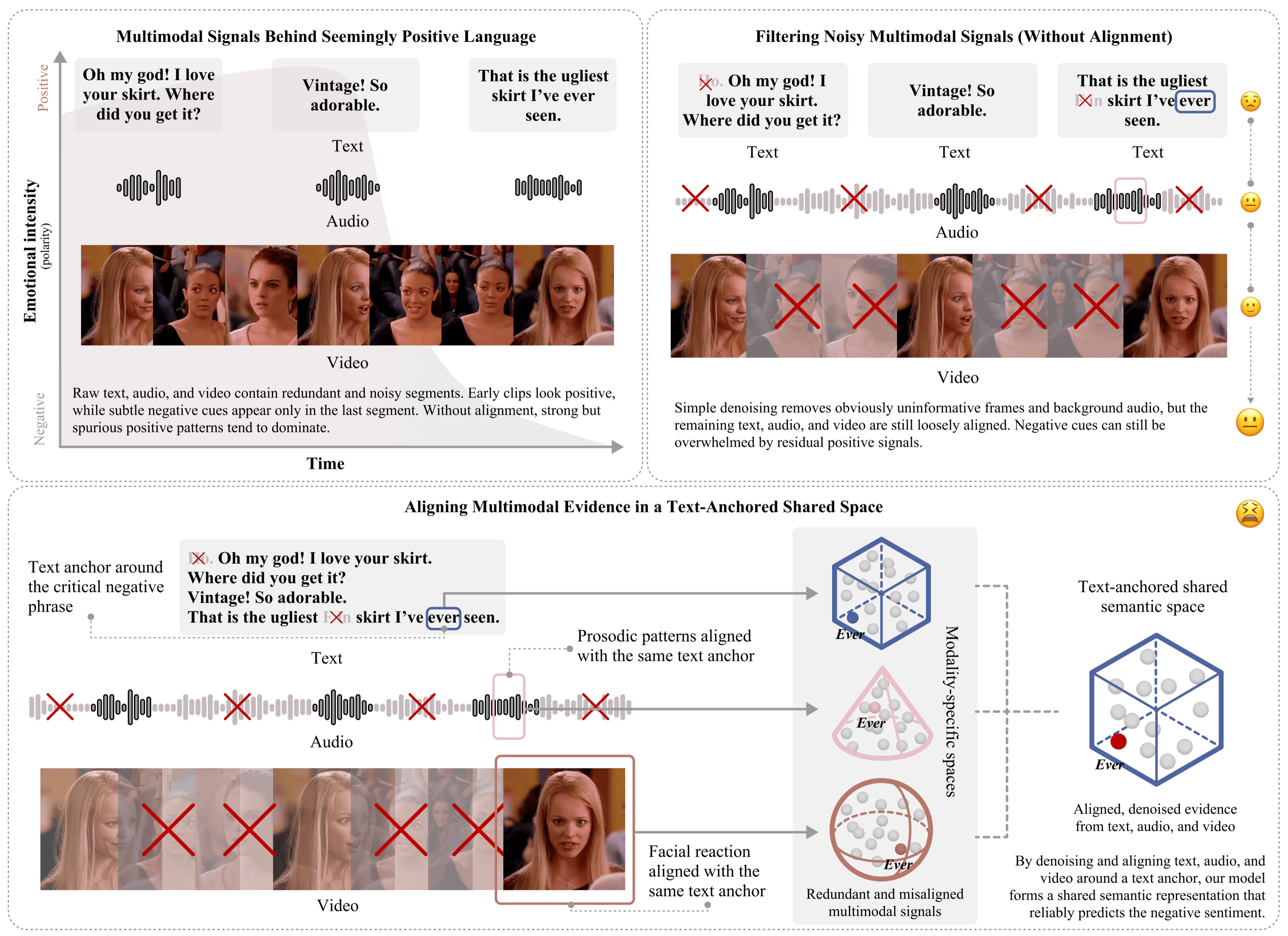
In real social communication, text, voice, and facial behavior do not always line up cleanly. Everyday cases like irony, sarcasm, hesitation, or mixed emotional expression can produce multimodal evidence that is redundant in some places and contradictory in others. If each modality is handled too independently, strong but misleading cues can dominate while weaker but task-relevant signals get washed out. Projecting all three modalities into one shared semantic space before fusion keeps those disagreements visible to the classifier instead of averaging them away.
Method
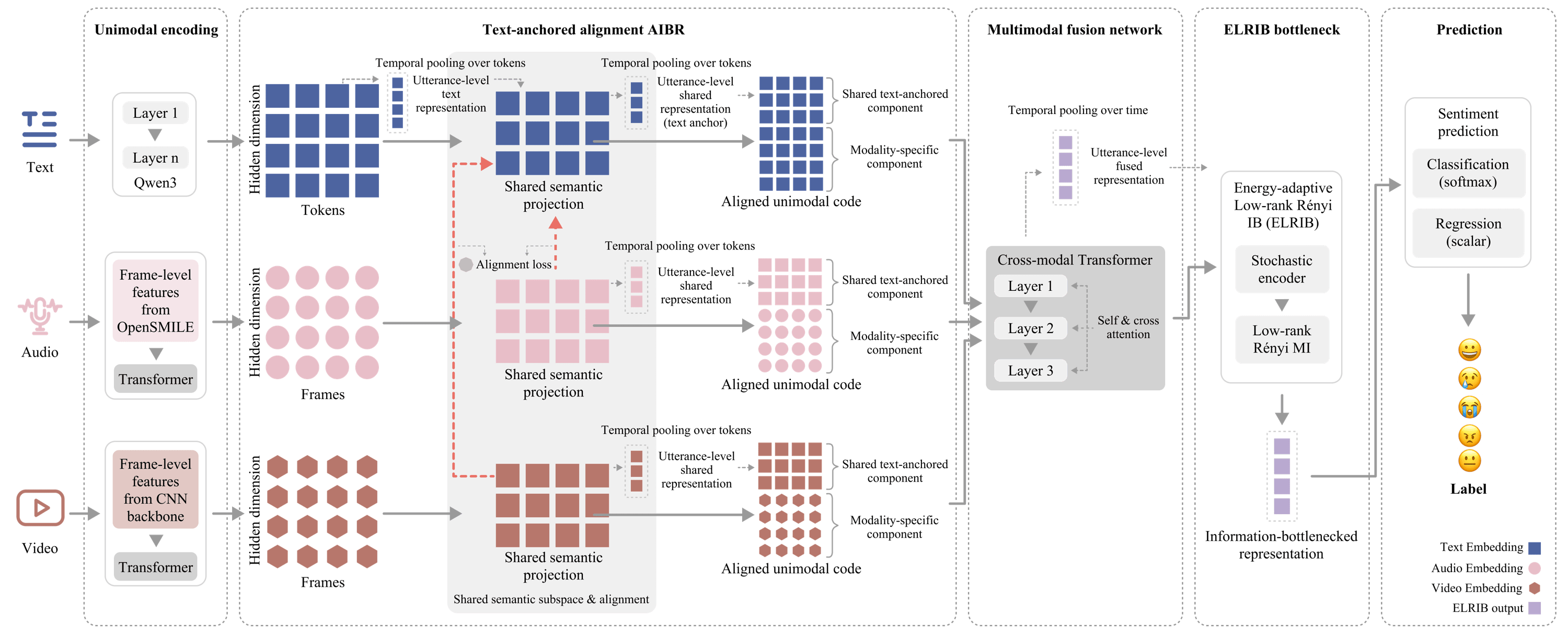
The model adds two components on top of separate text, audio, and video encoders. AIBR projects audio and video into a shared semantic space anchored by a Qwen-3 text encoder, putting all three modalities in one coordinate system before fusion. ELRIB follows the cross-modal transformer. It compresses the fused representation through a low-rank Rényi information bottleneck whose effective rank is selected per batch from the eigenspectrum, replacing the fixed-rank truncation used by prior matrix-based estimators.
Analysis
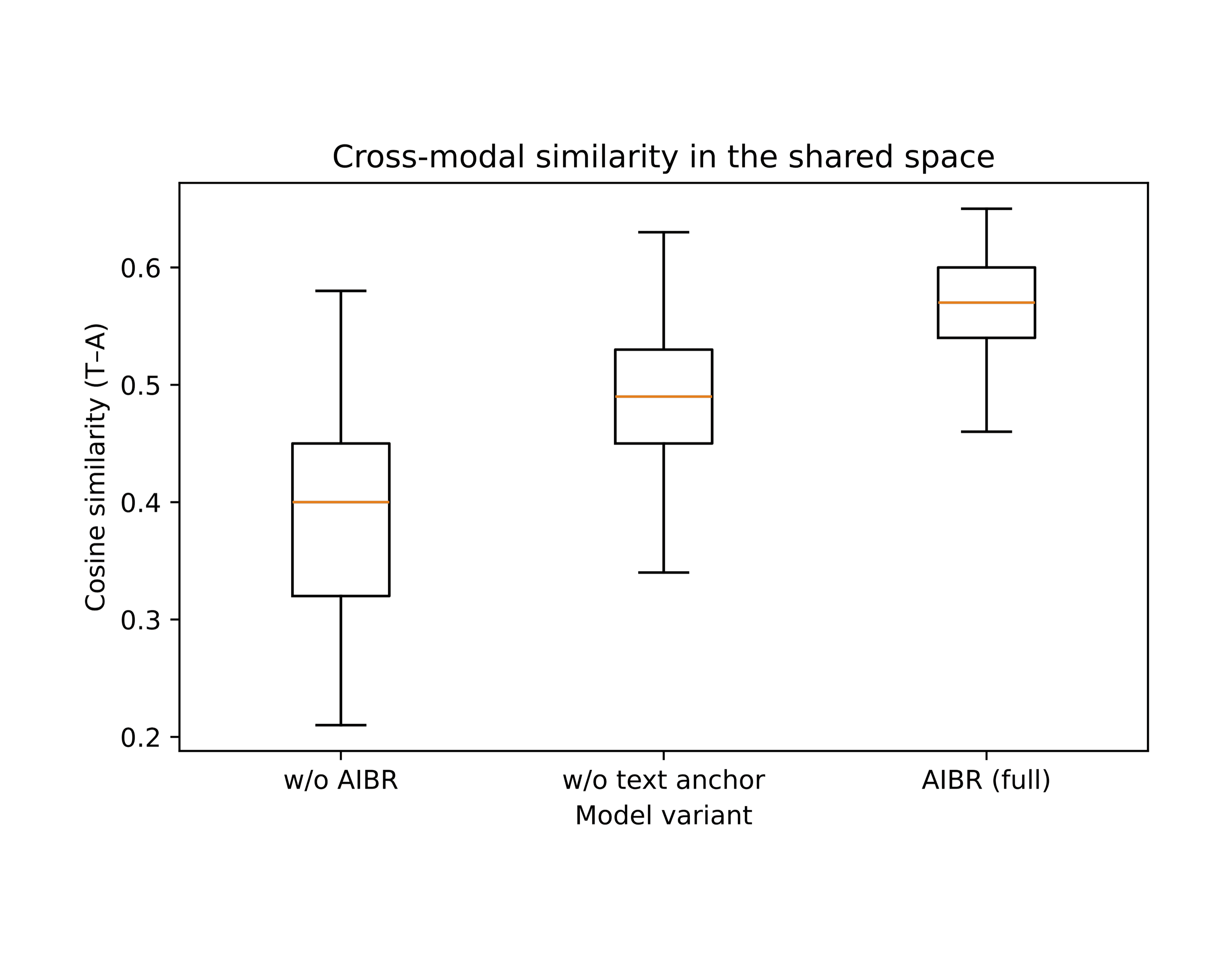
Cross-modal agreement. Cosine similarity between text and audio in the shared space across three variants. Removing AIBR or the text anchor both reduce agreement and widen the spread. The full model lifts the median and tightens the distribution.
Adaptive rank. Performance against fixed truncation rank on MOSI and MOSEI. The red star marks the rank ELRIB selects automatically per batch. It lands inside the optimal plateau on both datasets, with no grid search required.
Citation
@article{zou2026aligned,
title = {Aligned Information Bottleneck for Multimodal Social Sentiment Analysis},
author = {Zou, Runqi and Zhang, Jian and Ren, Anyu and Wang, Wenqing and Gao, Zhan and Wu, Jialun and He, Kai},
journal = {IEEE Transactions on Computational Social Systems},
year = {2026}
}